分かち書きとは?

分かち書き(わかちがき)とは、読んで字のごとく、一つの文を小さい語のまとまりに「分けて」「書く」ことです。機械学習の現場では、自然言語処理を実行するときの最初のステップとして、分かち書きを行います。
自然言語処理というのは、人間の言語である「自然言語」をコンピュータで分析するための処理のことです。漢字にするといかめしいですが、今ここで読んでいる「この文字」や「あの文字」も、"Thank you!"も全て、自然言語です。
👉参考記事:『自然言語処理(NLP)とは何か? 自然言語とプログラミング言語の違いを知ろう!』
自然言語は、コンピュータの言語である機械語や、その翻訳用言語であるプログラミング言語とは、言葉のルールや構成が大きく違います。
そのため、そのまま自然言語データをを分析しようとしても、コンピュータがうまく処理してくれません。
そこで登場するのが、機械学習の一分野である「自然言語処理」です。自然言語処理の実行は5つのステップに分かれ、「分かち書き」は、その第一ステップに位置付けられます。
👉参考記事:『自然言語処理の5つの実行ステップとは?「曖昧さ」への対応策としての機械学習』
分かち書きの具体的なやり方
分かち書き=形態素への分解!
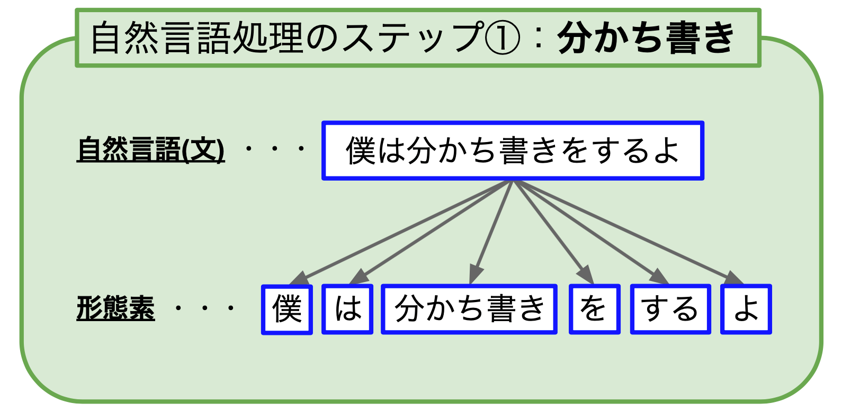
分かち書きによって分割された複数の小さい語のまとまりのことを「形態素(けいたいそ)」と呼びます。形態素とは、「それだけで意味をもつ、これ以上分割できない最小の語の単位」のことです。
例えば、「わたし」「あなた」「星空」「キレイ」「の」「に」といった語は、これ以上分割すると意味をなさなくなるので、形態素と言えます。試しに、「わたし」を「わた」と「し」に分割すると、意味が通りません(もちろん「綿」と「市」と読めなくもないですが、もともとの意味から変わってしまいます)。
分かち書きの作業では、語がもつ情報の質を考えていくために、与えられた一つの文を、こうした形態素へと分解するのです。
分かち書きをやってみよう!

出典:かわいいフリー素材集「いらすとや」
では、具体的な例をみてみましょう。
自然言語処理のタスクとして、下記の文が与えられたとします。
- 「眩しい光と発見に感動を覚えた」
この自然言語文を処理するために、機械学習ではまず、次のように分かち書きを行います。
- 眩しい(※) / 光 / と / 発見 / に / 感動 / を / 覚え / た
(※)「眩しい」の「い」は、意味や文法上の機能をなさないけれども、一つの形態素として成立するとする見方もあります。
先ほどみたように、「眩しい」は「眩」と「しい」には分けられませんし、「発見」を「発」と「見」に分けたら形態素としては不合格でしょう。
逆に、「覚えた」のように、「覚える」という基本動詞の語幹「覚え」と、過去を表す助動詞である「た」という異なる2つの形態素が結合して一語に見える場合もあります。
これを、「覚えた」で一つの形態素と判断してしまったら、分かち書きの作業としては失敗です。
このように、分かち書きは、文を構成する語を、まるで科学における元素分解や、数学における素因数分解のように、細かいけれど意味のある単位の語(形態素)に分割するというステップです。



