
自然言語処理とは?
自然言語処理は、日本語や英語といった自然言語をコンピュータ処理させる技術です。機械学習では、①分かち書き、②形態素解析、③構文解析、④意味解析、⑤文脈解析の順に、bag of wordsモデル、TF-IDF、LDA等のアルゴリズムで実行します。
自然言語処理とは何か?
自然言語処理の定義と役割
自然言語処理とは、自然言語の言語としての特性を踏まえて、コンピュータに処理をさせる技術のことです。
自然言語というのは、私たち人間が日常書いたり話したりしている日本語や英語のような、自然な言語のことです。
私たちは日常的に、あまりに見事に言葉を使いこなしているので強く意識することはありませんが、実は、自然言語は「意味を曖昧なまま表現するツール」であり、そのために「一つの文に対して複数の解釈ができる」という特性を持っています。
他方、「自然」言語というからには「自然じゃない」言語も当然あるわけです。
この「自然じゃない」言語というのは実は色々とあるのですが、ここで対比すべきなのは、プログラミング言語、つまり自然言語を機械語に翻訳するための言語でしょう。
機械は、人間とは異なり、異なる複数の解釈が存在している状態をうまく処理することができません。
したがって、コンピュータなどの機械を使いこなすためには、言葉に含まれた情報が機械へと正しく伝わるように、言葉の意味や値を一つに確定させる必要があります(この「言葉の意味や値が一つに確定している状態」のことを難しい言葉で「一意性」と言います)。
そこで登場したのが自然言語処理です。
自然言語処理は、機械学習を始めとしたコンピュータサイエンスの一分野として、曖昧さの塊である人間の言葉を、一意性をもったデータへと変換するための重要な役割を担っています。
(「人間はコトバを話す生き物だ」とはよく言われた話ですが、全くその通りで、実は、私たちが普段何気なく行なっている会話は、最新のコンピュータでもそのままではうまく処理できないレベルの高度な知性を必要とする作業なのです。)
このように、自然言語処理は、「曖昧さ」という自然言語の特性を前提にしながら、自然言語をデータとしてうまく取り扱っていこうよ、という考え方なのです。
自然言語とプログラミング言語の違い
上で説明したように、自然言語とプログラミング言語には、「曖昧さが許されるかどうか」という違いがあります。
これは、具体的にはどういうことでしょうか?
具体的な例をとりながら、それぞれの言語特性を見ていきましょう。
自然言語の曖昧さ

まず、自然言語について。
自然言語は、情報を曖昧なまま伝えることができる言語で、一つの文に対して複数の意味の解釈が可能であるという特性を持ちます。
例えば、「白い服の大きい幼稚園児」という文が、どんな幼稚園児のことを表現しているかを想像してみましょう。
ちゃんと考えると、この文の意味には少なくとも2つの異なる解釈が存在することがわかります。
- 白い[服の大きい]幼稚園児 → 服がダボダボな色白の幼稚園児
- [白い服の][大きい幼稚園児] → 白い服を着た、背が大きい幼稚園児
これは、「白い」「大きい」という形容詞がそれぞれどの名詞を形容しているのか、つまり、言葉の「係り方」が一つに定まっていないために、文が一意性のない曖昧な状態になっている例だと言えます。
ここで、注意していただきたいのですが、「曖昧だから良くない文だ」と言いたいわけではありません。
確かに、学校や職場では、「言葉をちゃんと使わないと曖昧になって相手へと正しく伝わらないから気をつけなさい」と習うことが多いでしょう。
実際に、上司とのタスクのやり取りで、曖昧な指示をはっきりとさせないまま、間違って解釈をして、指示とは異なる作業に多くの無駄な時間を費やしてしまった、という経験をお持ちの方も少なくないはずです。
しかし、後にも説明するように、自然言語をうまく処理するために私たちが用いているのは、言葉そのものの理解だけではありません。
私たちは、言葉や文自体の解釈だけでなく、前後の文脈から意味を推測したり、相手との関係性や、過去の出来事の記憶や経験から類推したり、あるいは発話者の顔色や表情であるとか周囲の人の「空気」を読み取ったり、というように、複数のアプローチによって自然言語を処理しています。
そして、こうした複数のアプローチは決して無駄な作業というわけではありません。
複数の方法の掛け合わせで意味を確定するというやり方のおかげで、私たちは、言葉だけで一意的に表現する方法よりもはるかにシンプルな形で言語を用いることができる、言い換えるならば、「短くスッキリと表現できる」のです。
このように、自然言語は、意味を確定するために人間が使う様々な方法を背景にして、複数の解釈可能性を曖昧にしたまま表現できるという特性を持っています。
プログラミング言語

他方、プログラミング言語はどうでしょうか?
プログラミング言語は、人間が機械と正しく情報伝達することができるように作られた言語です。
現状の機械は、人間とは異なり、「空気を読む」といった高度な状況判断ができません(もしかするとそのうち空気を読み出すAIが登場するかもしれませんが)。
したがって、人間から出された指示を間違いなく処理したり、機械自身が物事を適切に考えたりするためには、情報の媒介である言語が一意的である必要があります。
そのため、プログラミング言語は、一つの文が常に一つの解釈に定まるように、あらかじめ言語運用に関する明確なルールが決められています。
次のような文をみてみましょう。
- 3*15-6
- print('Hello world')
一般的なプログラミング言語だと想定してこれらの文を日本語に翻訳すると、一つ目は「3かける15ひく6」、二つ目は「”Hello world"という語を画面上に出力しなさい」という命令文です。
ここで、文が一つの意味に定まるとはどういうことでしょうか?
例えば、一つ目の文について、人間がこの文を自然言語として読めばどういうことになるかを考えてみましょう。
真っ白な紙にこの「3*15-6」と鉛筆で書いて誰かに見せてみたら、ある人は何かの暗号文だと思うかもしれません。
あるいは、プログラミング言語を学んだことのある人であれば、3かける15ひく6」を実行して「39」と答えるかもしれません。
もしくは、「さんあすたりすくいちごーろく」と読んで、バンド名はたまたITベンチャーの名前だと思う人だって出てくるかもしれません。
「いやいやそんなバカな」と思われるかもしれませんが、この文が自然言語として表現されている以上、この文を書いた人が「これこれこういう意味だ」と断言しない限り、意味を確定することはできないのです。
その一方で、プログラミング言語としてこの文をコンピュータに入力した場合はどうでしょうか?
この場合、誰が、どんな場面で、どんな服を着て、どんなキーボードを使って、どんな顔をしながら入力したとしても、コンピュータはその言語のルールで定められている通りの処理を実行します(一般的なプログラミング言語であれば、「3*15-6」を入力すると「3かける15ひく6」という計算を実行します)。
プログラミング言語では、一つの文の意味が必ず一つに確定するように、ルールが定められているからです。
このように、プログラミング言語では、自然言語とは異なり、常に語や文の意味が一つに定まるため、解釈が複数生じるような曖昧さは持ち合わせてはいません。
自然言語の曖昧さ
自然言語とプログラミング言語の「曖昧かどうか」という違いがわかったところで、「自然言語が曖昧である」ということの意味をもう少しだけ深掘りしてみましょう。
自然言語の曖昧さには、上述した掛かり方の問題の他に、解釈多様性の余地がいくつか存在します。
自然言語の曖昧さ①:「低い」は肯定的?否定的?
程度を表すような形容詞、例えば「高い」「低い」「大きい」「小さい」といった言葉は、文脈や情報の受け取り手の価値観などによって、その言葉が肯定的なのか否定的なのかの解釈が曖昧になる場合があります。
次の例をみてみましょう。
- 店の支払い金額が低い → 肯定的
- 店の質が低い → 否定的
- 店の敷居が低い → ???
まず、一つ目の例である「店の支払い金額が低い」は常識的に考えて、肯定的な文であると考えられます。
これは、店でサービスを受けるのであれば、金額が高いよりも低い方が良いと考えるのが合理的だからです。
次に、二つ目の「店の質が低い」はどうでしょう?
これも、常識的に考えれば、否定的な文であると解釈できるでしょう。
同じお金を払うのであれ、わざわざ質の低い店を良しとする人はいないはずです。
しかし、三つ目の「店の敷居が低い」に関しては、金額や質のような解釈が難しくなってきます。
なぜなら、店の敷居の低さに関しては、その店を選択する人の好みに左右されてしまうからです。
一見、敷居が低い方を好む人が多そうに思えなくもないですが、敷居の高い高級店ばかりを好んで用いる人も少なくありません。
したがって、「店の敷居」といった言葉にかかる場合の「低い」は、その程度が高い方が好ましいのか低い方が好ましいのかの方向性が定まらないために、言葉に対する解釈の違いが生まれることになります。
このように、自然言語では、「程度が低い」という意味自体は確定している場合でも、程度に対する解釈の違いによって、文の意味が曖昧になる場合があります。
自然言語の曖昧さ②:本当に言いたいこと(”主訴”)は?
自然言語を曖昧にしているもう一つの場合として、主訴(しゅそ)の問題があります。
主訴とは、要は、「結局何が言いたいの?」に答える主張のことです。
具体的な例から考えてみましょう。
ある日、友人とカフェで近況報告をし合っている時に、友人から次のようなことを言われたとします。
- 「(最近)楽しい話がないんだよね」
- 「(最近)楽しい話に感動したんだよね」
どこにでもよくありそうな会話ですが、これら1と2には、情報の受け手にとって次のような大きな違いがあります。
- 「楽しい話がない」 → 楽しい話 < 話がない → 「話がない」が主訴
- 「楽しい話に感動した」 → 楽しい話 ? 感動した → 主訴が不明
1つ目の文では、話し手の言いたいことは明らかです。
話し手には楽しい話が思い浮かんでいないのですから、言いたいことは、要は「話がない」ということです。
他方で、2つ目の文では、話し手は具体的な過去の経験をもとに話しています。
そのため、1とは異なり、「楽しい話」自体も主訴になり得る一方で、「感動した」ことも主訴になり得てしまい、ここに文の曖昧さが出現します。
実際に、この文を誰かに話してみると、とても興味深いことが起こります。
Aさんに「楽しい話に感動した」と言えば「へぇ!どんな話?」と返ってくるのに、Bさんに言えば「感動することって大事だよね!泣いた?」と返ってくる、というように、聞き手によって返答が異なるのです。
これは、Aさんが「主訴=楽しい話」と解釈したのに対して、Bさんが「主訴=感動した」と解釈したこと、つまり主訴の曖昧さに対する解釈の違いによって起こったことだと考えられます。
このように、自然言語では、文の意味自体は確定しており、その中に含まれている言葉に対する捉え方が同じ場合であっても、「文の中でどこが重要な点なのか(主訴)」が曖昧になることで、解釈の多様性が生じる場合があります。
自然言語の曖昧さへの対応
これまでみてきたように、自然言語は非常に曖昧なツールです。
この曖昧さは、「短くスッキリ表現できる」という便利なメリットがある一方で、情報の受け手による解釈の違いを生むリスクを孕んでもいます。
この問題に対して、人間は、既に述べたように、前後の文脈から意味を推測したり、相手との関係性や、過去の出来事の記憶や経験から類推したり、あるいは発話者の顔色や表情であるとか周囲の人の「空気」を読み取ったり、というように、複数のアプローチによって自然言語を処理しています。
しかし、残念ながら、現状の科学技術では、機械がそうした人間のアプローチをそのまま獲得・利用することは困難です。
したがって、自然言語を、その言葉や文の集合だけをみて、できる限り曖昧さがなくなるように判断する必要があります。
そのための方法として考えられるのが、「周辺の語、共起性を見る」というアプローチです。
自然言語においては、ある単語が存在したとしても、その単語単体では、その意味・価値は確定できません。
また、文は、単語1、単語2、単語3・・・という複数の単語が集まってできており、さらに文章は、文1、文2、文3・・・と、複数の文が集まってできています。
そのため、個々の単語は、その単語が位置付けられている文章全体の文脈のもと、周辺にある単語や文の状況次第でその意味を変化させていると考えられます。
したがって、自然言語を、その言葉や文の集合だけをみて、できる限り曖昧さがなくなるように判断するためには、まずは単語に注目して、それらの単語が周辺の語や、周辺語との関係性との間でどのような役割を果たしているかを考えていく必要があるのです。
自然言語処理は、まさに、こうした「解釈の曖昧さへの対応策」として、「周辺の語、共起性を見る」というアプローチにもとづいて実行されています。
自然言語処理を実行するための考え方
自然言語処理の5つの基礎ステップ
「解釈の曖昧さへの対応策としての自然言語処理」という考え方は、機械学習のデータ前処理でも採用されています。
自然言語の曖昧さは機械学習のインプットデータとして不適切な状態であるため、学習によるモデル化を行う前に、曖昧さを解消することでデータの「一意性(意味や値が一つに確定していること)」を担保する必要があるからです。
この機械学習の前処理として行われる自然言語処理は、次の5つの基礎ステップに基づいています。
これらの基礎ステップは、以下の1〜5の順に行われます。
| 順序 | 内容 |
| 1 | 分かち書き |
| 2 | 形態素解析 |
| 3 | 構文解析 |
| 4 | 意味解析 |
| 5 | 文脈解析 |
ただし、5の文脈解析は、非常に高度な処理が求められるため、システムとしてはまだ実用化されていません。
それでは、順に見ていきましょう。
自然言語処理の基礎ステップ①:分かち書き
自然言語処理の第一ステップは「分かち書き」です。
分かち書きは、読んで字のごとく、一つの文を小さい語のまとまりに分けて書くことです。
分かち書きの作業では、語がもつ情報の質を考えていくために、与えられた一つの文を、「それだけで意味をもつこれ以上分割できない最小の単位」に分割します(この単位のことを言語学の分野では”形態素、けいたいそ”と呼びます)。
具体的な例をみてみましょう。
「眩しい光と発見に感動を覚えた」という文が与えられたとします。
この自然言語を処理するために、機械学習ではまず、次のように分かち書きを行います。
- 眩しい / 光 / と / 発見 / に / 感動 / を / 覚え / た
ここで、「それだけで意味を持つこれ以上分割できない最小の単位(形態素)」とはどのような意味かと言うと、例えば、「眩しい」という言葉は、「光が強くてまともに見ることが出来ない」という意味を持つ単語ですが、これを「眩 / しい」のように分割してしまうと、「眩」の方はまだしも、「しい」が全く意味をもたない語になってしまいます。
あるいは、「と」「に」「を」という語は、一文字という小ささながら、日本語を理解している人であればその意味を理解できる単位を維持できています(とはいえ、「と」の意味を説明しろと言われれば非常に難しいですが・・・)。
このように、分かち書きは、文を構成する語を、まるで科学における元素分解や、数学における素因数分解のように、細かいけれど意味のある単位の語(形態素)に分割するというステップです。
自然言語処理の基礎ステップ②:形態素解析(けいたいそかいせき)
自然言語処理の第二ステップは「形態素解析」です。
形態素解析は、分かち書きによって最小単位へと分割された後の語(形態素)に品詞付けを行う、つまり語に役割を付与する作業です。
品詞とは、「単語を文法的な機能や形態などによって分類したもの(Wikipedia)」のことで、概ね下記のように分類されます。
(「文節」や「活用」等の用語については、本記事の範囲を超えているため説明を割愛します)
| 単独で文節を形成できるか | 活用するか否か | 品詞(大) | 品詞(小) |
| できる(自立語) | 活用する | 動詞 | - |
| 形容詞 | - | ||
| 形容動詞 | - | ||
| 活用しない | 名詞 | 代名詞 | |
| 数詞 | |||
| 連対詞 | - | ||
| 副詞 | - | ||
| 接続詞 | - | ||
| 感動詞 | - | ||
| できない(付属語) | 活用する | 助動詞 | - |
| 活用しない | 助詞 | - |
例えば、前述の文を形態素解析すると、次のように品詞が付与されることになります。
- 眩しい-(形容詞)
- 光、感動、発見-(名詞)
- 覚える-(動詞)
- と、に、を-(助詞)
- た-(助動詞)
このように意味を持つ最小単位の語(形態素)に品詞をつけること、あるいは、分かち書き+品詞付けの作業全体のことを形態素解析と呼びます。
ちなみに、形態素解析は、次の2点について注意が必要です。
- 形態素解析器によって分かち書きや品詞付けの粒度が異なる
- 今回は例として日本語の文を扱っているが、英語の文を解析する場合は挙動が少し異なる(一般的に、英語の文は初めから単語間にスペースが設けられているため、日本語と比べると単語分割が楽)
自然言語処理の基礎ステップ③:構文解析
自然言語処理の第三ステップは「構文解析」です。
構文解析は、形態素解析で得られた単語間の関係性について可視化する作業です。
構文解析によって、単語間の係り受け関係(どの語がどの語を修飾、補足、接続等しているかの関係性)が可視化され、文法的にどのような構造をしているのかを調べることが可能です。
中学高校の英語の授業で必ず出てくる「構文」という分野は、まさに英語についてこの構文解析を行なった結果を学習する学問分野だと言えます。
再度、先ほどの例文で考えてみましょう。
- 例文:「眩しい光と発見に感動を覚えた」
このうち、「眩しい光と発見」に注目してみます。
形態素解析によって、「眩しい光と発見」は、「眩しい(形容詞)+光(名詞)+と(助詞)+発見(名詞)」であることがわかっています。
ここで、形容詞は名詞や動詞を修飾する(”係る”)語で、「と(助詞)」は語と語、あるいは句と句、文と文を繋ぐ言葉なので、「眩しい光と発見」は、次のどちらかの構文(文の構造)に絞られることになります。
- [眩しい光]と[発見]
- 眩しい[光と発見] ...「眩しい光と(眩しい)発見」という文から同じ意味の「眩しい」が一部省略されて括られた形
このように、構文解析は、品詞を付与された形態素同士の関係性に注目することで、文の構造を明らかにすることを目的としています。
自然言語処理の基礎ステップ④:意味解析
自然言語処理の第四ステップは「意味解析」です。
意味解析は、構文解析をした文から正しく意味内容を解釈するために行われる作業です。
本記事冒頭の「白い大きな服の幼稚園児」でも触れた通り、自然言語では通常、一つの文に対して解釈の仕方(つまりは構文理解)が複数存在することなります。
この中から正しい解釈を選択するために、意味解析はとても重要な処理だと言えます。
意味解析で行う解釈の選択は、形態素の意味や構文そのものからは判断することができません。
そのため、係り受け関係を判断するために、「どの語同士の組み合わせが最も頻繁に使われているか」というデータから結論を導き出すことが一般的です。
具体例でみていきましょう。
先ほどの構文解析で、「眩しい光と発見」は次のいずれかの構文であることがわかりました。
- [眩しい光]と[発見]...(A)
- 眩しい[光と発見]...(B)
意味解析では、これらの語同士の組み合わせのうち、「どちらがよりありそうか?」をデータから判断することになります。
ここでの論点は、「眩しい」が「発見」に係っているとみるべきかどうか、です。
一般的に、「眩しい」は「光」と同時によく使われるものの、残念ながら「発見」と同時に使われるケースはほとんどありません(眩しいと言えるほどの発見を一度でいいからしてみたいものです)。
したがって、「眩しい」は「光」に係る言葉であって「発見」には係っていない、つまりは(A)の構文理解が正しいという結論を導くことになります。
このように、意味解析では、言語学の分野では「コロケーション」とも呼ばれる、語同士が一緒に用いられる頻度の傾向データをもとに、文の意味に対してアプローチしています。
自然言語処理の基礎ステップ⑤:文脈解析
自然言語処理の第五ステップは「文脈解析」です。
文脈解析は、一つの文に含まれる語や語同士の関係のみに注目するのではなく、それらを踏まえて、文章中に現れる他の語との関係や文章の背景に隠れた知識などといった情報をもとに、文の意味を理解しようと言うアプローチです。
しかしながら、文脈解析は、ありとあらゆる複雑な情報をインプットデータとすることになり、意味解析よりもはるかに難しい処理となってしまいます。
そのため、現状では、文脈解析を行うシステムはまだ実用化されておりません。
私たち人間が、いかに難しい処理をいとも簡単にこなしているかが、このことからも窺いしれるでしょう。
ちなみに、文脈解析と同じく「文章中に含まれていない語に注目する」という観点から行われる解析に、「照応解析」と呼ばれる処理があります。
照応解析とは、次の例のように、代名詞や指示詞などの指示対象を推定したり、省略された名詞句(ゼロ代名詞)を補完する処理のことです。
- A君はコーラを飲んだ。B君もその飲み物を飲んだ。 → その飲み物=コーラ
- A君は外車を買った。次の日(A君は)それに乗ってドライブに行った。 → 主語省略(A君は)、それ=外車
主語の省略が頻繁に起こる日本語では、この照応解析が特に重要になります。
例えばGoogle翻訳などの翻訳機で、隠された語を補完せずに機械翻訳することで全く別の文に翻訳されてしまったという経験をお持ちの方もいらっしゃるでしょう。
この照応解析も、人間にとっては当たり前にこなしているものの、機械にとっては全く簡単ではない例の一つだと言えるかもしれません。
自然言語処理を機械学習で実行する
自然言語処理でよく用いられる2つの機械学習アルゴリズム
これまで、プログラミング言語に対比される中での自然言語の「曖昧さ」という特徴、その曖昧さを踏まえてうまくコンピュータで処理するための自然言語処理の5つの基礎ステップについて、順にみてきました。
最後は、そうした「曖昧さ」を回避するための基礎ステップに基づいてつくられた、実際に機械学習の現場で実装される自然言語処理の代表的なアルゴリズムである、次の2つを紹介したいと思います。
- bag of wordsモデル
- TF-IDF
これらのアルゴリズムは、主に「意味解析」を目的に行われる学習モデルです。

ただし、それぞれのアルゴリズムを詳しく解説することは、本記事の範疇を越えるため行いません。
ここでは、概要だけに軽く触れて、詳細は別の記事に譲ることとします。
それでは、それぞれ、順にみていきましょう。
自然言語処理でよく用いられる機械学習アルゴリズム①:bag of wordsモデル
自然言語処理で用いられる機械学習アルゴリズムの一つに、「bag or wordsモデル」があります。
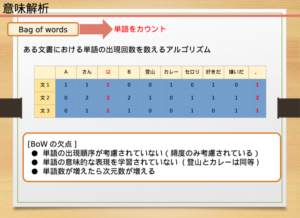
bag of wordsモデルは、ある文書における単語の出現回数を数えるアルゴリズムで、単語数を数えることにより、複数の文書を比較したり類似性を測定することが可能になります。
bag of wordsモデルでは、各文書の単語数を一覧表で表示します。
この表では、単語と文書がベクトル化という効果的な方法で保存されており、行見出しには単語、列見出しには文書、各セルには単語数が入力されます。

自然言語処理でよく用いられる機械学習アルゴリズム②:TF-IDF
自然言語処理で用いられる別の機械学習アルゴリズムに、「TF-IDF(Term Frequency - Inverse Document Frequency。以下、TF-IDF)」があります。
TF-IDFとは、ある記事に含まれる単語を使って、その記事のトピックを判断するという方法です。
ここで、TF、IDFという言葉は、それぞれ次の意味をもちます。
- TF:文書内の単語の出現頻度を表す指標
- IDF:単語を含む文書が多いと小さくなる指標(Thisなど多くの文章で使われている言葉は小さくなる)
この2つの指標の掛け合わせて出来たのがTF-IDFで、特定の文書にしか出現しない単語の値を評価する指標として機能しています。





